🧠 一、我们想解决什么问题?
咱们做机器人训练时,最理想的情况是:
- 拥有大量图像 + 动作对(比如:图像是“你看到桌子上的杯子”,动作是“抓取杯子”)
但这个代价太高了,因为:
- 每一个动作都需要遥操作记录,成本高、数据少。
- 网上虽然有无数视频(比如做饭、打扫等),但都没有动作标签。
所以这篇论文要解决的核心问题就是:
“我可不可以只用视频(图像+语言),就学出‘合理的动作表示’,然后少量微调就能用在机器人上?”
🧩 二、他们是怎么解决的?——3个阶段!
这篇论文的方法叫做 LAPA,核心是三个阶段:
✅ Step 1:
从视频中学“潜在动作”
就像学语言之前我们要知道“单词”,他们的第一步是:
能不能从图像对(比如当前帧、下一帧)中提取出“离散的动作”表示?
他们的做法是:
- 用一个VQ-VAE模型来学习帧之间的“动作变化”,并量化为一个离散 token。
- 这个 token 可以理解为:视频中这个时刻发生了某个原子动作,比如“手往右移动一点”或者“手下压一点”。
这个阶段得到的:是一个“潜在动作编码器”,可以把视频帧差异编码为一串离散动作 token。
✅ Step 2:
训练一个“潜在动作模型”
现在我们把互联网上的“机器人视频”、“人类视频”都喂进去,用刚才学到的编码器标注出潜在动作序列(虽然不是真实动作,但代表行为变化)。
然后训练一个模型,输入是:
- 当前图像
- 自然语言指令
输出是:
- 一串潜在动作 token
这个过程就像是训练一个语言模型一样,预测“动作序列”。
这一步没有用真实动作,仅用“潜在动作”。
✅ Step 3:
在少量真实机器人数据上微调
最后,为了让这个潜在动作序列真正转为“机器人能执行的连续动作”,我们只需要:
- 用小规模真实机器人数据,学一个小的映射模型:把潜在动作 → 真实动作。
这样我们就完成了“从无标签视频 → 学动作表示 → 少量微调 → 真正部署”。
🧪 实验结果上有什么亮点?
他们在三个场景中做实验:
- 跨任务:训练任务A,测试任务B(模型泛化性好)
- 跨环境:换不同环境(比如换颜色、换背景)
- 跨形态:人类视频 → 机器人动作
他们发现:
- LAPA 比很多 baseline(包括用真实动作训练的)都更稳,更泛化。
- 即使只用人类视频来预训练,也能 transfer 到机器人动作上。
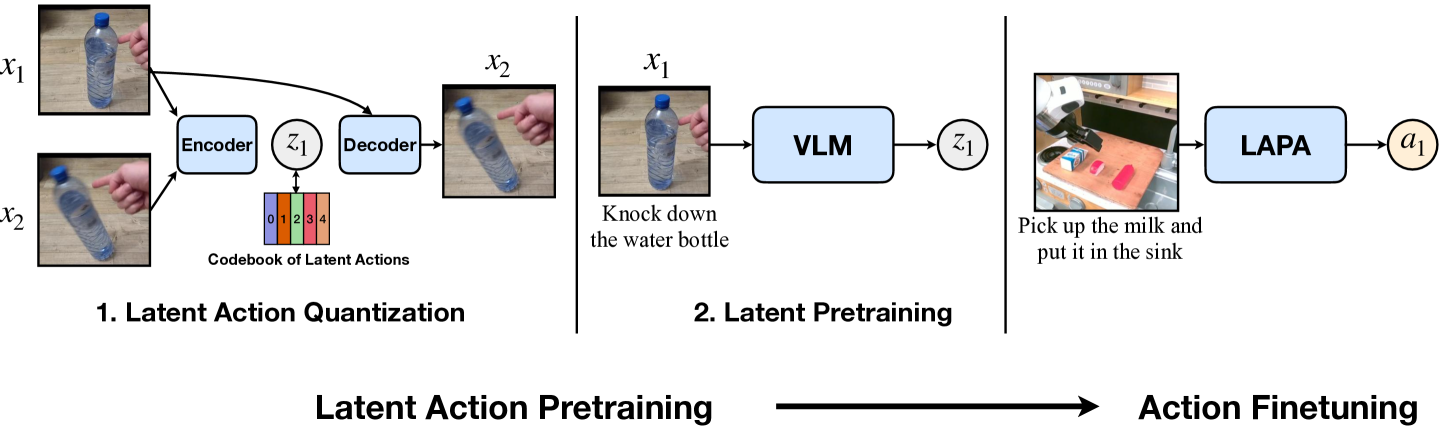
🎯 总体结构:三部分、两个阶段
- 左边:Latent Action Pretraining(潜在动作预训练)分为两步
- 右边:Action Finetuning(动作微调)才用到真实机器人动作
🧩 Step 1: Latent Action Quantization (潜在动作量化)
训练阶段:
- 输入:两个连续的视频帧 x_1, x_2(比如:手指靠近瓶子 → 瓶子倒了)
- 模型结构:
- Encoder:把 x_1, x_2 输入后,输出一个向量表示 z_1,表示“从 x1 到 x2 的变化”
- 然后将 z_1 映射到最近的一个codebook 中的离散 token(比如 token 2)
- Decoder:接收 x_1 和 token 2,重建出 x_2
训练目标:
- 让 decoder 重建的 \hat{x}_2 尽可能接近真实的 x_2
- 同时保持 token 离散、稀疏(VQ-VAE loss)
推理阶段:
- 模型固定,用来把任意帧对编码为离散动作 token
- 得到的是一种“潜在动作表示” z_1,离散的整数 token
✅ 目的是:把“视觉上的变化”学成离散的潜在动作 token,作为后面训练的“伪动作标签”
🧩 Step 2: Latent Pretraining (潜在动作预训练)
这个部分开始用语言啦!
训练阶段:
- 输入:
- 当前图像 x_1
- 自然语言指令(比如 “Knock down the water bottle”)
- 模型是:VLM(Vision-Language Model)
- 类似 Flamingo、BLIP、M3AE 等结构
- 输出:
- 预测潜在动作 token z_1,来自 Step 1 学出来的 codebook
✅ 目的是:让模型学会“看图+听语言” → 猜应该执行哪个潜在动作
推理阶段:
- 输入一张图 + 一个任务
- 输出一串潜在动作 token,类似“动作语言”
🧩 Step 3: Action Finetuning (动作微调)
这一步才是让机器人能真正“动起来”。
训练阶段:
-
输入:
- 当前图像
- 语言指令(如“把牛奶放进水槽”)
-
模型结构:
- 把图+语言送进刚刚预训练的 VLM,得到潜在动作 token(如 token 12)
- 用一个小的 MLP 模型(LAPA 模块),把 token 映射为真实动作 a_1:可以是 Δpose、关节角等
-
目标是最小化动作误差:预测动作 a_1 要接近真实标签(遥操作数据提供的)
推理阶段:
- 和训练一样,只是此时机器人开始执行输出的动作了。
✅ 总结三块中每个模型:
| 步骤 | 模型名 | 输入 | 输出 | 训练目标 |
|---|---|---|---|---|
| Step 1 | Encoder + VQ-VAE Decoder | 图像对 x_1, x_2 | 潜在 token z_1 | 重建 x_2 |
| Step 2 | VLM (vision-language model | 图像 + 指令 | 预测 token z_1 | 与 Step 1 输出 token 一致 |
| Step 3 | LAPA 模块 (MLP) | token z_1 | 实际动作 a_1 | 最小化真实动作误差 |
你想不想我们画一个具体例子,比如:“拿起瓶子”这个动作,从 Step1 到 Step3 怎么流动的?或者我们看一下论文里的公式部分再连一下。
🎯 Q:这个 VLM 是用已有模型微调的吗?
✅ 答案是:
是的,他们用的是已有的多模态模型(Frozen pre-trained VLM)进行微调,而不是从头训练。
📖 论文里明确写了:
“We leverage a frozen pre-trained visual encoder (e.g., from CLIP or SigLIP) and a language model head to learn latent actions.”
也就是说,他们用的 VLM 是类似于 CLIP 的结构:
- 视觉编码器 是从 CLIP、SigLIP 或 ImageBind 迁移过来的,Frozen(不更新参数)
- 语言模块(文本编码器 or Transformer),可以是微调过的
- 然后接一个小的 token 分类头,输出 codebook 中的 token 概率